TCP-like congestion control and the meaning of "inflight"
How a misunderstanding of "inflight packets" caused a years-long bursty retransmission bug in Geph
Sosistab2 is an encrypted transport protocol used extensively in both Geph and Earendil. It is a generic adapter that takes "pipes" that are entirely datagram-based and unreliable (such as obfsudp, an obfuscated UDP-based protocol), and overlays on them functionality that most networked applications need — end-to-end encryption, authentication, as well as a reliable TCP-like streams.
This overall makes it much easier to develop new and exciting obfuscation protocols, since they only need to implement a really easy datagram-based interface without worrying about retransmissions, correct encryption, or anything of that sort. But it also means that I have to to implement something along the lines of TCP, in order to multiplex reliable streams on these unreliable transports.
I thought I had a pretty good understanding of how TCP worked, and there's plenty of prior work in implementing a TCP-like protocol in userspace (like uTP, QUIC, etc). So back in 2020 when I was writing Geph 4.0, I hacked together something that seemed to work reasonably well, and off into production it went.
The problem
But over the past few years, there's been on recurring complaint about Geph that I was just not able to diagnose: for some users, Geph's SOCKS5 proxy mode, which tunneled the content of TCP traffic over sosistab2's TCP-like reliable streams, was extremely slow — 10 times or more slower than network-layer VPN mode, which directly overlays operating-system TCP functionality onto sosistab2's underlying unreliable transports. What made this problem much more annoying was that this only happened sporadically in some network conditions, and pretty much only in China.
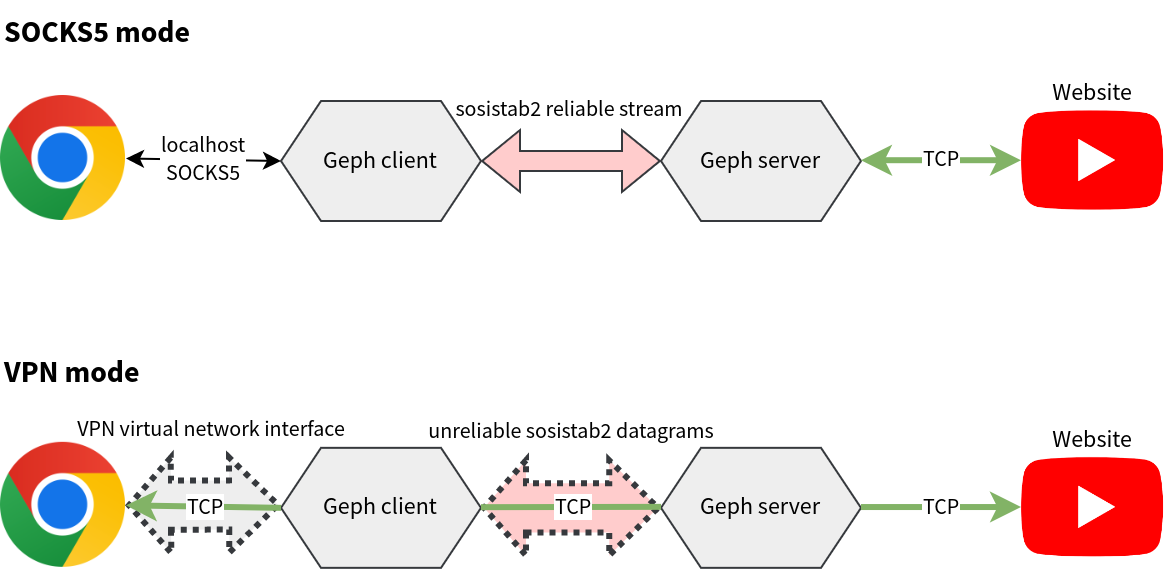
What could be wrong? As the picture above shows, the only substantial difference between SOCKS5 and VPN mode is that in the former case, reliable transmission is handled by sosistab2 streams, while in the latter, it's handled by TCP. So the answer had to be that in some weird network conditions, sosistab2's reliable stream algorithm performs much worse than TCP.
I was not too bothered by this at first, though I was not able to reliably reproduce this behavior. TCP, especially the Linux kernel TCP implementation, has had decades of optimization to squeeze as much performance out of rapidly evolving underlying networks as possible, while sosistab2 streams were rather quickly hacked together without any of fancy-sounding algorithms like fast retransmit, proportional rate response, pacing, etc.
So I decided to implement some of these techniques. Most notably, I tested a variety of modern congestion control algorithms — the rules that that regulates how many packets can be unacknowledged at the same time — settling on implementing BIC, a TCP congestion control algorithm similar to CUBIC, the default used by the Linux kernel. Compared to the previous algorithm I used (a variant of HSTCP, which is old but easy to implement), BIC certainly ramped up to fill up bandwidth more quickly and resulted in less packet loss. While testing on my own first-world Internet connection, it behaved a lot more like a good TCP implementation, so I rolled it out to production Geph servers, hoping that this would solve the mysterious transient handicap to SOCKS5 performance the Chinese users were complaining about.
Unfortunately, it didn't. But without a good way of reproducing the problem, I did not have a better solution than to tell complaining users to please try VPN mode instead.
A diagnosis...
My first reproduction of the mysterious SOCKS5 slowdown came entirely serendipitously. I had just moved to Miami, and there was no internet in my new home. To use my phone as a hotspot without paying through the roof for bandwidth, I quickly got myself a Visible eSIM, which is one of the few truly unlimited options.
And lo and behold, Geph on this new network setup exhibits the exact behavior the Chinese users complained about! In conditions where unproxied traffic could push 5 MB/s, traffic tunneled through Geph in VPN mode might achieve 4 MB/s, but almost half the time, tunneling through Geph's SOCKS5 mode gave me excruciating 100 KB/s speeds.
I also noticed something strange: the connections would always start out fine, but once the speed almost got to the speed limit of the connection, speeds would suddenly collapse and never recover.
I set up a test server that would dump out tons of verbose logs about what's going on in sosistab2's guts, and I rather quickly found out the culprit. When I download a file through the server, the congestion control algorithm would allow data to be sent faster and faster to my computer by increasing the congestion window — the maximum number of packets allowed to be unacknowledged at the same time. Once the pipe fills up, a small amount packet loss would happen, which would normally trigger retransmission of the lost packets and decrease the congestion window; the window would then grow until loss happens again.
But that is not what I observed at all. Instead, once the retransmissions started, the stream would almost grind to a halt. The retransmitted packets kept getting retransmitted over and over; if 10 packets needed to be retransmitted, 8 or 9 packets would need to be retransmitted yet again. And with every retransmission, congestion control would kick in, reducing the congestion window. By the time all the packets that needed to be retransmitted finally got through and were acknowledged, the congestion window would typically be at a tiny value, slowing everything down. Worse, most of the time the connection was simply stuck in this state of retransmission and slowing down, making average speeds very poor.
After a bit of thought, I rather quickly realized why this would happen. In the internal state of a sosistab2 stream, I maintain an inflight buffer: a list packets that we've sent, but the other side hasn't acknowledged yet. It looks something like this:
| Sequence number | Next retrans time | Retrans count | Body |
|---|---|---|---|
| 1 | 2022-03-01 15:45:00 | 0 | "Packet 1 content" |
| 2 | 2022-03-01 15:46:05 | 0 | "Packet 2 content" |
| 3 | 2022-03-01 15:47:10 | 0 | "Packet 3 content" |
| 4 | 2022-03-01 15:48:15 | 0 | "Packet 4 content" |
| ... | ... | ... | ... |
Note that we keep track of the scheduled retransmission time of every packet — if a packet is still not acknowledged by this time, it is immediately retransmitted. And we try to keep the size of this entire buffer (let's abbreviate it \( \mathsf{inflight} \)) from growing beyond the congestion window (\( \mathsf{cwnd} \)), by disallowing more entries to be added unless the congestion window is greater than the length of this list.
Retransmission times are set by adding to the original sending time the retransmission timeout, a worst-case estimate of the network latency calculated by Karn's algorithm, the de-facto standard in TCP. What this means, though, is that any burst of consecutive packets that is lost would be retransmitted at the same speed.
This is very bad. If sending packets at, say, 1000 packets per second caused enough congestion to lose many consecutive packets, retransmitting them at the same speed would cause just as much congestion, and lead to just as much packet loss. This is doubly so if the congestion resulted from an abrupt decrease in available network bandwidth, which I guess happens a lot in China (where internet backbones are routinely congested), and certainly on my mobile hotspot (Visible is basically lowest-priority Verizon service). In that case, the retransmissions would face even more loss than the original. The bizarre behavior observed, of repeated retransmissions and slowdowns, is thus entirely explainable.
...without a solution?
The problem seemed to stem from the fact that given the way I implemented the inflight buffer, the standard congestion avoidance strategy of reducing \( \mathsf{cwnd} \) could not reduce the rate of retransmissions, even though every explanation of TCP I've read somehow assumed that it would overall slow down transmission. But I wasn't sure what the solution was.
My first guess was that the congestion window should somehow control transmission on top of the size of the inflight packet list. If the \( \mathsf{inflight} \geq \mathsf{cwnd} \), we would stop all transmissions and retransmissions until it falls below the congestion window.
This unfortunately failed miserably. It led to connections permanently getting stuck when a large fraction of packets in the inflight window are lost:
- \( \mathsf{cwnd} \) would be reduced (generally to \( \mathsf{cwnd} / 2 \))
- Transmission and retransmissions immediately cease, since \( \mathsf{inflight} \geq \mathsf{cwnd} \)
- At this point, only acknowledgements can shrink the \( \mathsf{inflight} \).
- But enough packets were lost that the \( \mathsf{inflight} \) never shrinks below \( \mathsf{cwnd} \). Nothing ever gets through after this!
So this was clearly not the solution. I realized that there must be something very wrong with the way I understood the overall outline of congestion control common to TCP, QUIC, and beyond.
My first guess was that keeping track of per-packet retransmission times was somehow wrong. Early TCP specs like RFC 2988 generally refer to the "RTO timer" (retransmission timeout timer), which when fires triggers the retransmission of the earliest unacknowledged packet, so I tried an implementation where we indeed only have one RTO timer. That, of course, got rid of the floods of retransmitted packets I was seeing, but in exchange, large bursts of lost packets could only be retransmitted at a rate of 1 packet per round-trip time, which caused unbearable delays.
Later, after some intense digging around and even looking at some TCP and QUIC source code, I realized that these specs were "wrong" for modern networks where large windows are common; the Linux kernel, for instance, definitely keeps track of separate timers for every packet. This is especially the case for protocols using selective ACK (SACK), which includes sosistab2. So maybe my inflight buffer implementation wasn't that wrong?
By this time, I was sick and tired of trying to "properly" fix this problem. I ended up writing an obviously wrong stopgap hack to fix the worst of "retransmissions causing more congestion" — rate-limiting all retransmissions to 100 retransmissions per second.
The meaning of "inflight"
But this hack of course would cause slowdowns, though not as bad as those caused by congested retransmissions, so I occasionally would still think about correctly fixing this problem. One day when I was in the shower, I suddenly had an idea as to what might be the key error that led to these bursty retransmissions.
All this time, I had understood the "inflight number of packets" that the congestion window limits to mean "the total number of packets yet to be acknowledged", and thus the size of the inflight buffer. It made sense: these packets where logically "on their way", inflight, to the destination.
But what if the "inflight number of packets" really meant the best estimate of the number of packets actually on the wire, making way to the destination? That turns out to not be \(\mathsf{inflight}\), the length of the inflight buffer!
Instead, we need to subtract all the packets that were lost, since they are no longer taking up any space "on the wire". A good estimate of this would be the number of packets in the inflight buffer with expired next-retransmission times, since those are set as a conservative deadline after which the packet, if still unacknowledged, would be considered lost. Let's call this \(\mathsf{estimated\_lost}\). Then, the objective of congestion control would be to try to keep \[\mathsf{inflight} - \mathsf{estimated\_lost} \leq \mathsf{cwnd}\] rather than \(\mathsf{inflight} \leq \mathsf{cwnd}\).
I then realized that this meant that I could use \(\mathsf{cwnd}\) to throttle both new additions to the inflight buffer and retransmissions! That is, whenever the above inequality fails to hold, the sender simply wait indefinitely until it holds, avoiding transmitting any packet. Back when \(\mathsf{estimated\_lost}\) was not taken into account, this would, as I explained previously, lead to a deadlock since after \(\mathsf{inflight}\) is reduced by congestion control \(\mathsf{inflight}\) might never fall below \(\mathsf{cwnd}\), forcing me to conclude that retransmissions could not be throttled.
But now, even if \(\mathsf{cwnd}\) were to drop all the way to 1, eventually all inflight packets will time out and be considered lost, such that \(\mathsf{inflight} - \mathsf{estimated\_lost} = 0 < 1\). So the deadlock would not happen!
I quickly implemented this protocol in sosistab2, and after testing I happily discovered that the old pathological behavior was nowhere to be found. Reducing \(\mathsf{cwnd}\) on detection of loss immediately slows down both new packets and retransmissions, avoiding the repeated congestion and losses that excessively reduce \(\mathsf{cwnd}\). Performance was comparable to CUBIC TCP even on my horrible Visible hotspot (though still a bit slower than unconventional, rate-based algorithms like BBR).
The change was rolled into production, and most of the complaints about SOCKS5 performance disappeared.
Conclusion
The annoying thing, however, is that this bug would probably have never been solved if I did not have a random shower-thought guess. None of the sources I had read, including RFCs, StackOverflow posts, and college TCP textbooks, seemed to clearly define what exactly the "inflight packets" that the congestion window limited were.
Perhaps nobody mentioned this because everybody except me found it obvious that the congestion window limited \(\mathsf{inflight} - \mathsf{estimated\_lost}\) and not \(\mathsf{inflight}\), though more likely there aren't just that many people trying to reimplement TCP-like congestion control from scratch out there.
But in case somebody else does write something like sosistab2 and run into the same misconception as I did, I decided to write down my long-winded journey to understanding "inflight".