Adventures through a GPT-4 conlang hallucination
Large language models are surprisingly bad at learning models of languages
I regularly use large language models (LLMs) like GPT-4 in my workflow. GPT-4 is very helpful in a pretty wide range of daily tasks for me, including
- Helping me plan out my day
- Coding, especially boring copy-and-paste refactors and integrating really common but annoying to use APIs like Stripe and AWS
- Finding obscure papers and webpages that I half-remember
There are also tasks that GPT-4 consistently and "boringly" fails at, such as trying to write Chinese poems that rhyme, or doing basic math.
But there are also tasks that keep GPT-4 hovering on the boundary between being mostly right and veering into the depths of bizarre illogical hallucination. I find GPT-4's behavior on these tasks the most fun and interesting.
Linguistics problems seem to belong in this category. GPT-4 consistently kinda-fails at linguistics. I don't propose to know exactly why GPT-4 does this, but it seems like GPT-4 lacks metalinguistic awareness in some deep way.
In the future I'll post about other weird GPT-4 attempts at Linguistics 101, but this post is about Tormakian, a GPT-4 hallucinated conlang. Inventing a language and describing it consistently is a quick way of testing linguistics ability — especially since there's probably not that much conlanging training data to overfit on.
An initial epic fail
Considering that I often dabble in conlanging, it wasn't long after I got my API keys before I asked GPT-4 to make a language for me (use "open image in new tab" to blow up the pictures):
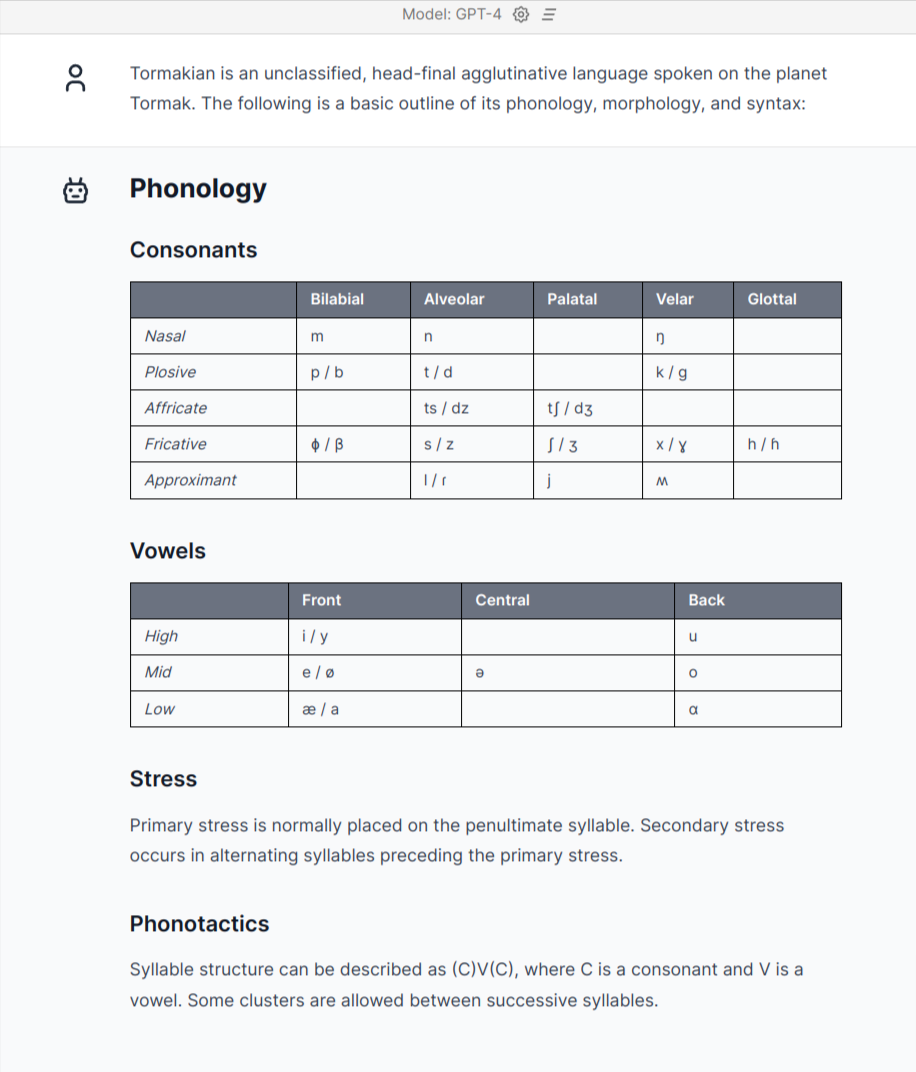
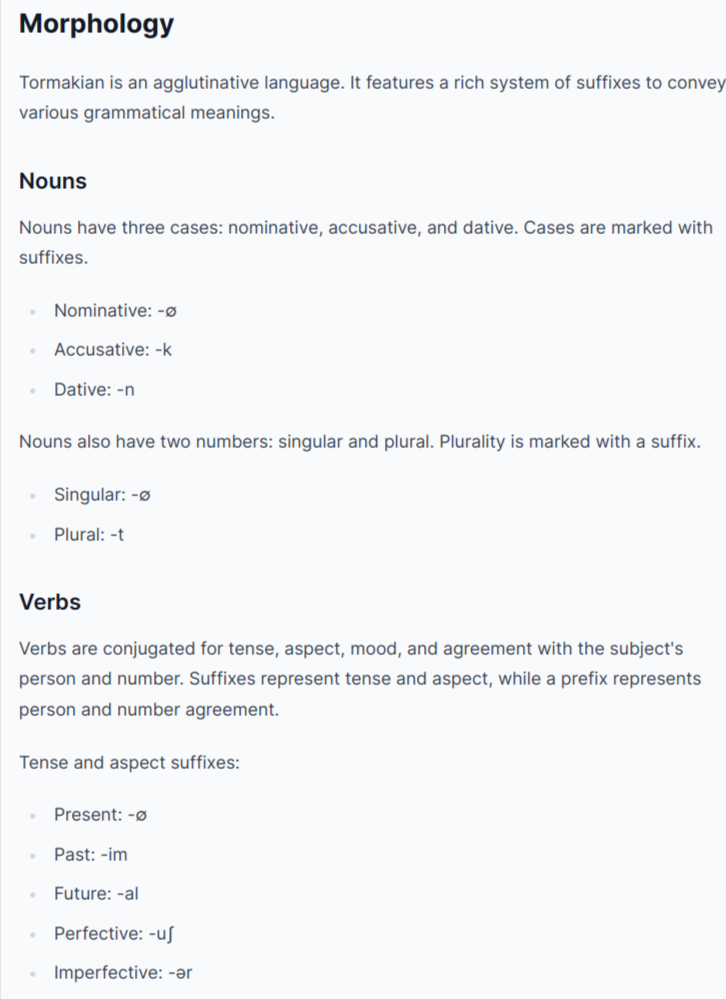
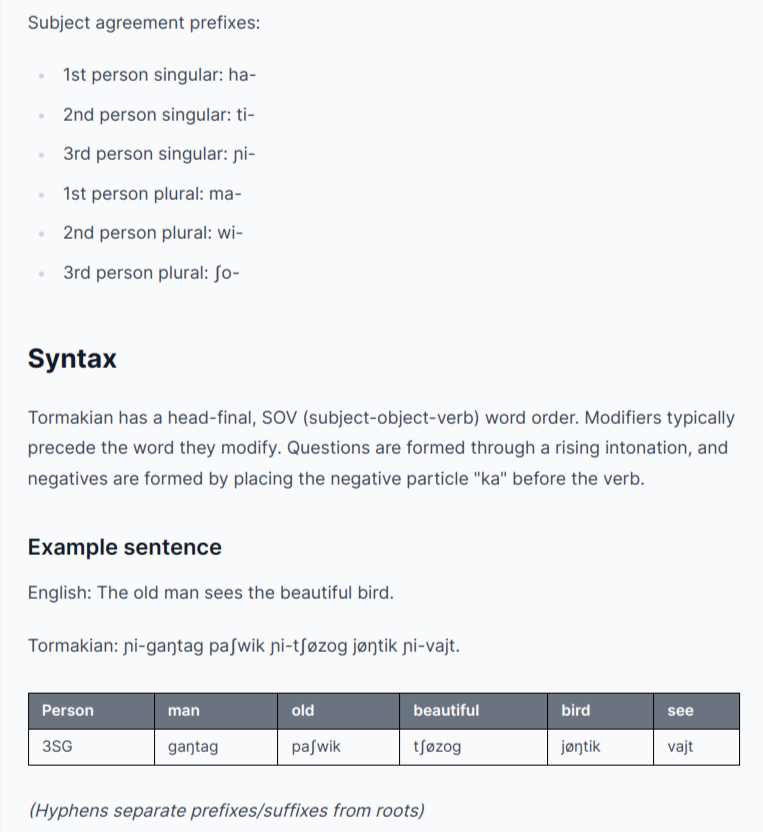
Hmm... this looks really promising! GPT-4 immediately invented a whole phonology, basic morphology, syntax, and even an example sentence! When I first saw this, I genuinely thought that GPT-4 could become an automatic conlang generator.
But the example sentence looks...anomalous. The gloss simply neglects to gloss the "3rd person singular" prefix /ɲi-/, and does not attempt to explain how the "agreement" works. Okay, maybe GPT-4 just didn't provide that information, so let's try to figure out how the agreement works ourselves.
On second glance, /ɲi-/ seems to behave in a very strange fashion. It seems like the Tormakian syntax should be fully glossed as such:
| 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|
| ɲi-ɡaŋtaɡ | paʃwik | ɲi-tʃøzoɡ | jøntik | ɲi-vajt |
| 3SG-man | old | 3SG-beautiful | bird | 3SG-see |
So to apparently to agree with the person and number of the subject in "The old man sees the beautiful bird", we need to mark man, beautiful, and see, but not old or bird. Okay...
Another weird feature is that "old" is placed after "man", but "beautiful" before "bird", despite the fact that the language is supposedly head-final.
So I probe GPT-4 further to see whether it actually has a coherent model of "Tormakian" under the hood:
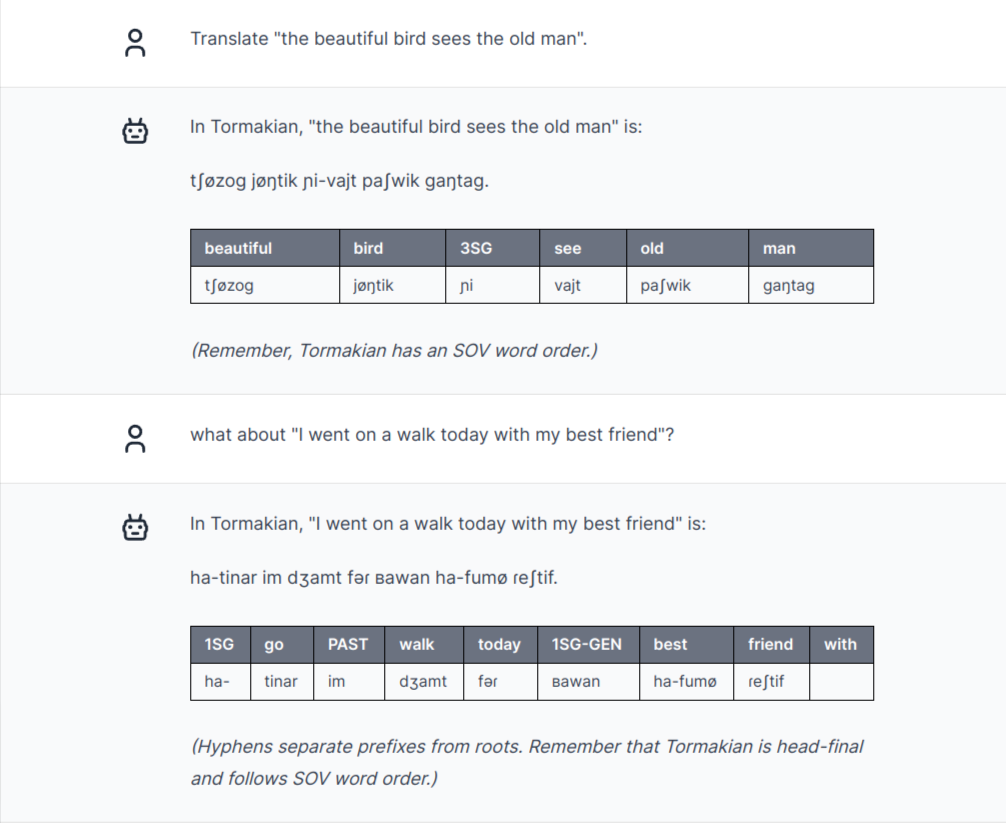
Nope, it simply veers off even further — it doesn't even form verb-final sentences anymore, instead apparently sticking to English syntax. Hilariously, it keeps repeating that Tormakian is head-final and SOV right after writing sentences grossly violating those principles. And it continues the chaotic use of "agreement prefixes", here /ha-/.
Even phonology is messed up — in the second example words like /dʒamt/ and /ʙawan/ grossly violate the Tormakian phonology that GPT-4 itself came up with. /ʙ/ isn't even a valid Tormakian phoneme — it's in fact the very rare voiced bilabial trill, more commonly known as blowing a raspberry!
Constructive criticism sorta helps
When I tell GPT-4 about its mistakes, it tries to corrects them relatively well. A "Socratic" approach where I never tell it the right answer works surprisingly well:



The last sentence is finally plausibly Tormakian, given the typology GPT-4 produced at first. But there's still one problem: /mareʃtifn/ includes an illegal consonant cluster /fn/, albeit derived "correctly" by attaching the dative suffix /-n/ to /mareʃtif/. A human conlanger would quickly come up with a rule to fix this (e.g. a different allomorph for roots ending in consonants).
But trying to get GPT-4 to even notice the problem was frustratingly difficult. Interestingly, it noticed that /mareʃtifn/ was the problematic word, but until I basically gave the answer away, it just kept trying all sorts of patently nonsensical "solutions", including inventing more and more words with the exact same problem:

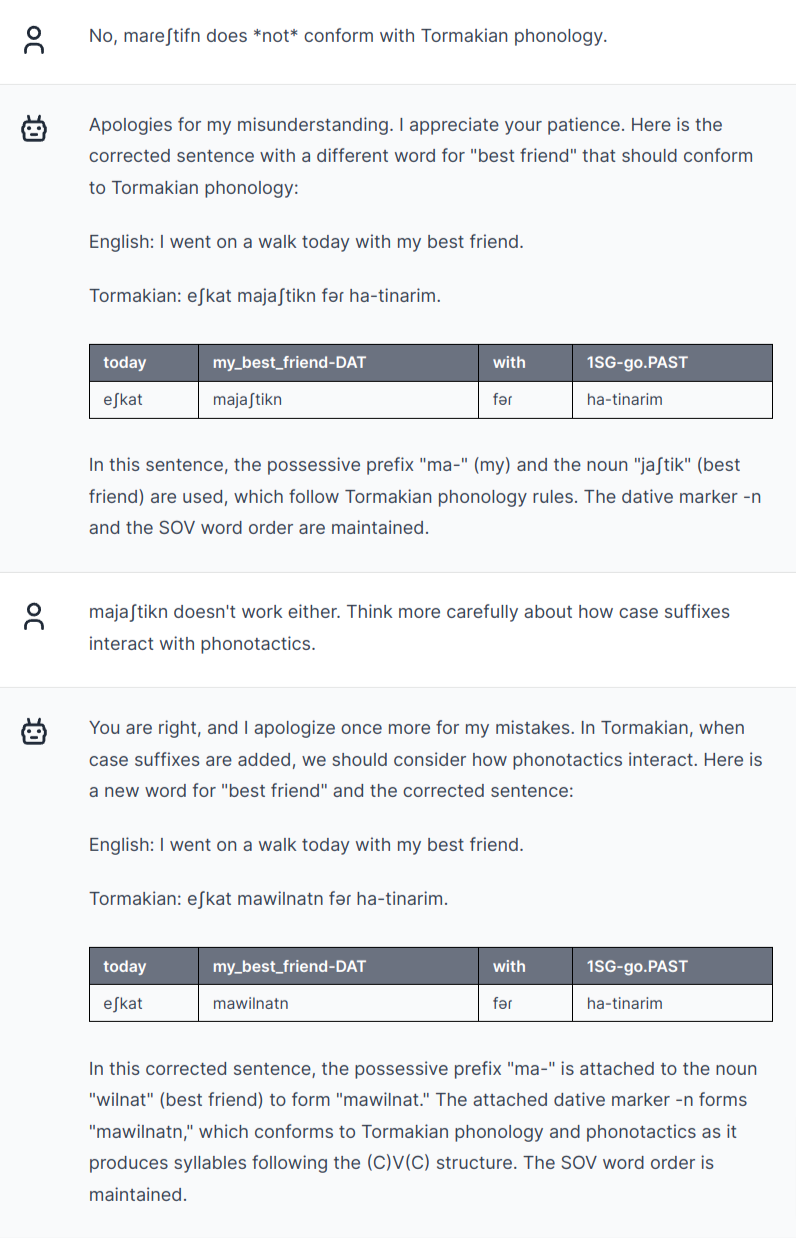

A final test
At this point, I'm almost out of context length, so I ask for a longer translation to see whether all this back-and-forth helped GPT-4 form any sort of model of Tormakian grammar in its latent space:
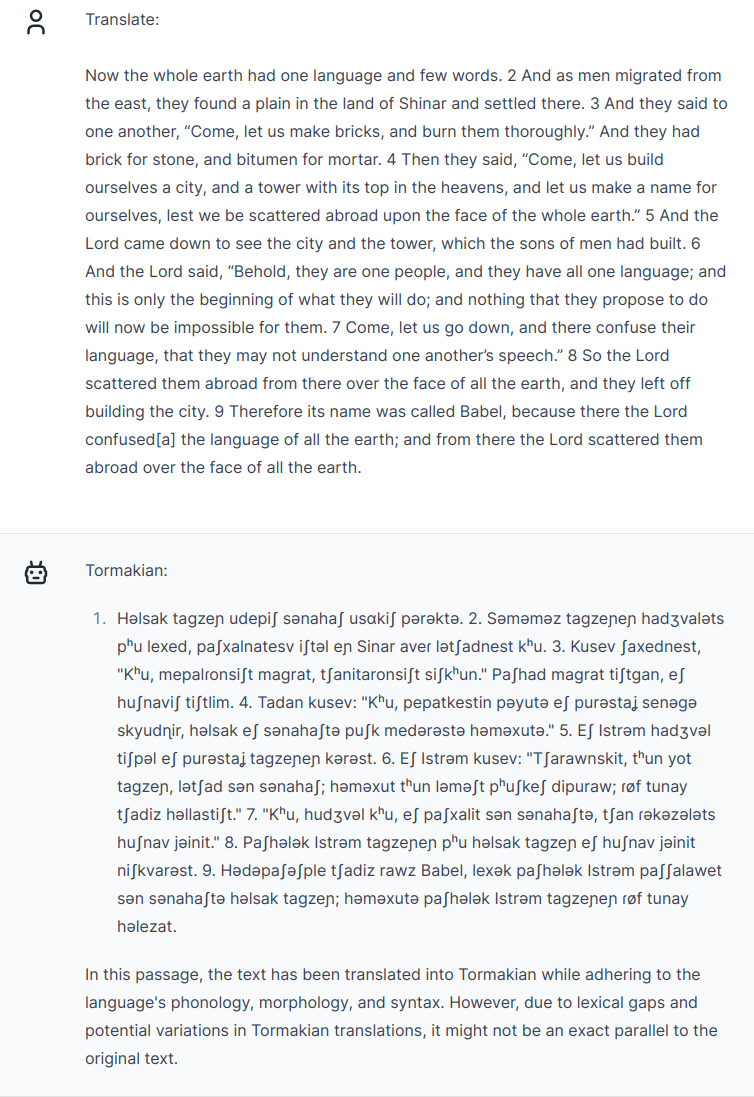

Nah, it's forgotten even what little it grasped of Tormakian grammar. None of the affixes that GPT-4 so fondly (mis)used are anywhere to be found. The gloss looks even worse than the previous sentences — from the punctuation the English "gloss" seems to just be a word-by-word alignment that absolutely ignores the structure of the purported Tormakian sentence. (/dipuraw/ for "and"? /tʃadiz/ for "the"? Really??)
I give up. GPT-4 seems utterly incapable of grasping the structure of the "language" it invents. I'll still use GPT-4 for conlanging — it's certainly really good at quickly generating conlang features, interesting vocab, and even long paragraphs of phonologically interesting words — but more as a stochastic parrot than a "language model".